Die Nacht, in der mein virtueller Server verbrannte
Am Morgen des 10. März fand ich in meinem E-Mail-Postfach Meldungen meines Monitorings aus der Nacht, dass einer meiner Virtual Private Server nicht mehr erreichbar ist. Es dauert einen Moment, bis mir klar wurde, was passiert war. Ein Lehrstück darüber, wie bedeutsam eine feuerfeste Backup-Strategie ist.

Punkt 2:30 Uhr in den frühen Morgenstunden des 10. März teilte mir das Monitoring meines Cloud-Anbieters OVH mit, dass das Virtual Private Server (VPS)-System sich nicht mehr meldete. Als ich die Meldung dann am frühen Morgen wahrgenommen habe, stellte ich fest, dass ich das System tatsächlich nicht mehr erreichen konnte. Eher ungewöhnlich, normalerweise läuft das System ohne Probleme durch. Außerdem konnte ich ein Postfach im Mail-Service bei OVH nicht erreichen, “Connection refused”.
Also in die Web-Oberfläche und den VPS durchstarten. Schon bei der Anmeldung in der Web GUI bei OVH traten seltsame Effekte auf, die Anmeldung hing – alles eher ungewöhnlich. Mit dem Verdacht eines größeren Systemausfalls bin ich mal auf die Suche gegangen. OVH hat verschiedene Status-Seiten in verschiedenen Sprachen: in französischer, englischer, manchmal auch in deutscher Sprache.
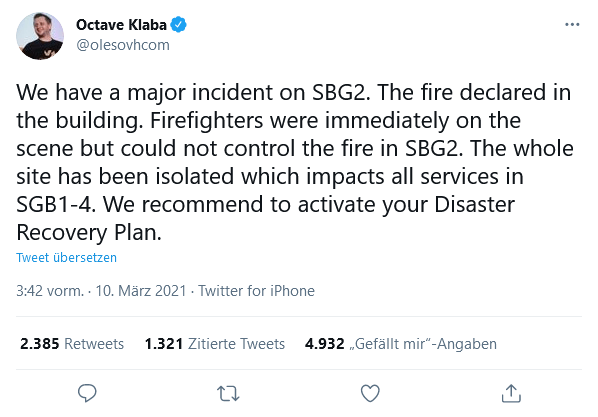
Alles nicht wirklich zielführend, bis ich über den Twitter-Account des OVH-Firmengründers stolperte, Octave Klaba. Dort war um 3:42 Uhr etwas zu lesen von einem Major Incident und Feuer im Rechenzentrum SBG2. Dort in Straßburg, wusste ich, lief mein virtueller Server.
Welches Rechenzentrum genau betroffen war, wusste ich nicht. Aber bei den eindrücklichen Bildern vom Ausmaß des Brandes und den Meldungen danach zufolge war das auch ziemlich egal. SBG 2 vollständig zerstört, SBG 1 zu einem Drittel zerstört, SBG 3 und SBG 4 abgeschaltet.


Backup
Backup hatte ich für meinen VPS nicht mitgebucht, sondern auf herkömmlichem Weg mit einem eigenen bewährten Backup-Script auf einen anderen Server gesichert.
Erster Check im eigenen Inventory: Full-Backup vom 1. März, inkrementelle Backups im gleichen Level vom 5. bis zum 9. März, am 10. März hat er keines mehr geschafft, es lief so nach 3 oder 4 Uhr morgens. Wenn das System nicht wieder kommt, dann gibt es wohl fast 24h Datenverlust, auf meinem Spiel-System eher unkritisch.
Daten-Replikation
Aber warum sollte das System nicht wieder kommen? Ein virtueller Server ist erst mal unabhängig vom Blech, auf dem er läuft. Man kann ihn auf jedem Basis-System starten. Wichtig ist die Datenplatte vom System. Die VPS bei OVH wurden beworben mit CEPH-Storage und dreifacher Replikation als ich sie damals gebucht hatte.
Dreifache Replikation klingt super. Die Frage ist: wo stehen die Knoten? Dazu hatte ich keine weiteren Informationen. Den Ausfall meines Spiel- und Bastel-Servers für ein paar Tage konnte ich problemlos verkraften, aber wann sollte ich mit der Wiederherstellung starten? Eigentlich hatte ich auf einen Restore aus dem Backup keine Lust. Darum entschied ich zu warten, bis zu einer endgültigen Klärung, was mit meinen Daten passiert ist.
Nachdem OVH seine eigene Infrastruktur und Web GUI wieder am Laufen hatte, konnte ich feststellen, dass mein System im Cluster 001 os-sbg1-002 laufen sollte, mit der Lokalisation SBG1. Gut, nach meinen aktuellen Informationen war ich dann bei einer Wahrscheinlichkeit von 2/3, dass mein System überlebt hat. Unter der Voraussetzung, dass CEPH-Knoten nicht im gleichen Raum standen, eher sogar noch etwas höher.
Alles verbrannt
Am 12. März kam allerdings die ernüchternde Mitteilung, dass os-sbg1 in Wirklichkeit in SBG2 stand und vollständig verbrannt ist. Nachdem der Totalverlust nun feststand und OVH ein paar Monate Gutschrift bei Neubestellung anbot, habe ich dann das System auf einem vergleichbaren VPS im Rechenzentrum in Gravelines restauriert.
Wie jedes Mal ist das wirkliche Zurückspielen eines vollständiges Backups mit einem gewissen Nervenkitzel verbunden. Erst mal die Keys zur Verschlüsselung heraussuchen, Backup entschlüsseln. Den neuen VServer im Rescue-System starten, Platte vorbereiten und über das Netz restaurieren. IPv4 wurde dynamisch zugewiesen, IPv6 wurde statisch hinterlegt, also das schnell gerade ziehen. Bootloader installieren und aktivieren und dann das System starten. Voilà! Das System ist wieder erreichbar. Im DNS die IP-Adressen korrigieren, die CNAMES ziehen dann automatisch hinterher und schon ist das System für alle Dienste wieder erreichbar.
Am nächsten Morgen noch sicherstellen, dass auch das Backup wieder gelaufen ist und dann kann man das System wieder vor sich hin laufen lassen.
Katastrophenfall-Wiederherstellung
Welche Erkenntnisse lassen sich nun aus diesem kleinen Lehrstück ziehen?
Seit vielen Jahren zitiere ich die Weisheit “Keiner will Backup, alle wollen Restore” in den Diskussionen zum Backup.
Disaster Recovery oder K-Fall-Wiederherstellung sind Dinge, die man auch für die lokale Infrastruktur immer im Hinterkopf halten muss. Feuer und (Lösch-)Wasser sind keine guten Freunde von Servern. Hier ist im Falle eines Falles immer mit Totalverlusten zu rechnen. Auf einer gewissen Flughöhe sind die CPU und der Speicher völlig egal, die lassen sich zeitnah wieder beschaffen. OVH war hier in der Lage, 10.000 neue Server in wenigen Tagen in Gravelines neu bereitzustellen.
Wichtiger sind die Daten. Hier hilft es nichts, wenn alle redundanten Storage-Knoten gemeinsam zerstört werden. Wenn, dann sollten diese Systeme schon in unterschiedlichen Brandabschnitten stehen. Und Backups sollten zudem auch außerhalb in ganz anderen Umgebungen gelagert werden. Entsprechend gesichert verwahrt, und am besten noch verschlüsselt auf den Medien. Aber auch die Entschlüsselung der Backups muss noch funktionieren, wenn die komplette Sicherungseinheit unbenutzbar wurde, d.h. der Key muss ebenfalls außerhalb gesichert sein.
Der Preis von verlorenen Daten
Verlorene Daten sind in der Regel heute auch nicht durch Geld zu ersetzen. Der Umfang der heute verarbeiteten Daten ist einfach so groß, dass wir nicht mehr darüber reden, dass einige Datentypistinnen die Papier-Bestellscheine des Tages erneut abtippen. Es geht um umfangreiche Datenbestände, die sich in den meisten Fällen nicht einfach so wieder rekonstruieren lassen. “Bitte alle Bestellungen vom 10. März noch mal ausführen” ist eine eher hoffnungslose Bitte an… ja, an wen denn?
Spezial-Appliances
Anders als bei den “normalen” Rechnern ist es bei Spezial-Appliances wie beispielsweise Firewalls oder Proxy-Systemen. Hier ist in der Regel die Beschaffung der Ersatz-Geräte selbst noch ein mögliches Problem, neben der vollständigen Sicherung von Konfiguration und auch hier Keys für die Verschlüsselung. Darum sollten auch hier die Cluster-Knoten oder redundanten Systeme in verschiedenen Brandabschnitten installiert sein. Brennt ein Rechenzentrum aus, kann das andere zumindest im K-Fall übernehmen.
Bleibt noch das Thema mit der Internet-Anbindung. Oftmals gibt es hier nur einen Übergabe-Punkt, sodass auch in einem Rechenzentrum die primäre Einführung existiert. In der Regel lässt sich hier aber die Ersatzleitung in das zweite Rechenzentrum legen, wenn das Gelände betreten werden darf. Alternativ können auch LTE-Ersatzleitungen mit dem Carrier verhandelt werden. Aber das ist deutlich schneller zu realisieren als alle Appliances neu zu beschaffen.
Was bietet die Cloud?
Während die lokalen Gegebenheiten sich relativ gut überschauen und verstehen lassen, und somit auch sehr einfach K-Fall-Szenarien beschreiben lassen, ist das in der Cloud ungleich schwerer. In der Regel kann man davon ausgehen, dass der Cloud-Anbieter sich über seine AGB und TOS weitestgehend aus allen Haftungen herausnehmen wird. In den gängigen Cloud-Umgebungen für Infrastucture as a Service (IaaS), also der Miete von Virtuellen Maschinen und Storage zur freien Verwendung, liegt das Backup in der Regel in der Verantwortung des Kunden. Manchmal werden Snapshots angeboten, die ersetzen aber in der Regel kein Backup.
Bei SaaS-Services gibt es manchmal ein rudimentäres Backup des Anbieters, oder mittlerweile viel häufiger Schnittstellen, an denen die gängigen Backup-Tools andocken können, um eine Datensicherung auch in eigener Verantwortung durchzuführen. Und in der Regel ist nicht das Backup die Herausforderung: Die granulare Wiederherstellung ist in vielfach die eigentliche Herausforderung, für die es spezielle Tools braucht.
Verfügbarkeits-Modellierung in der Cloud
Für Cloud-Rechenzentren gibt es weitere Herausforderungen. Bei AWS muss man auch mal virtuelle Maschinen durchstarten, um sie auf eine andere Hardware umzuziehen, weil Amazon an der ursprünglichen Hardware Wartung durchführen möchte.
Bei Azure ist es beispielsweise so, dass die Redundanz in Availibility Zones und Availability Sets beschrieben ist. Jede Availability Zone besteht aus mindestens einem Rechenzentrum, dessen Stromversorgung, Kühlung und Netzwerkbetrieb unabhängig funktionieren. Die Availability Sets hingegen sind nur unabhängige Server, Speicher und Netzwerk-Komponenten in einem gemeinsamen Rechenzentrum.
Azure in Deutschland bietet heute noch keine Availablity Zones. Wer diese benötigt, muss nach Azure Europe West, also Amsterdam, gehen. Hier zeigt sich, dass der Wechsel in die Cloud im Detail komplizierter ist, als es auf den ersten Blick scheint.
Kosten für Sicherheit
Und hier ist dann die Betrachtung wichtig, woher man kommt: verglichen mit dem Server-Schrank in der Besenkammer ist die Cloud vermutlich besser gesichert. Wer aber schon aus einem gewissen verfügbar modellierten Setup mit getrennten Server-Räumen auf dem eigenen Firmengelände kommt, muss darauf achten, dass er sich in der Verfügbarkeit nicht schlechter stellt als bisher. Und diese verbesserte Verfügbarkeit lassen sich die Cloudanbieter in der Regel bezahlen. Genauso wie alle anderen Themen. Wer schon mal im Calculator bei Azure versucht hat, eine Schätzung für seine Backup-Kosten bei Microsoft zu ermitteln, kann das vermutlich nachvollziehen.
Notfallplanung
Wichtig für alle Verantwortlichen ist tatsächlich, sich über die Risiken und die Auswirkungen von Ausfällen und Zerstörungen klar zu werden. Das kann strukturiert in einem Tool zur Notfallplanung passieren, dass kann auch mit der Hand am Arm in einem Wiki passieren. Wichtig ist nur die Betrachtung, ob nach einem K-Fall diese Dokumentation noch zugreifbar ist. Nicht zu vergessen sind auch regelmäßige Tests für die Wiederherstellung von Systemen. Nichts ist fataler als ein Backup, dass sich nicht restaurieren lässt.
Zum Autor
Oliver Paukstadt
IT-Security Consultant und IT-Architekt







